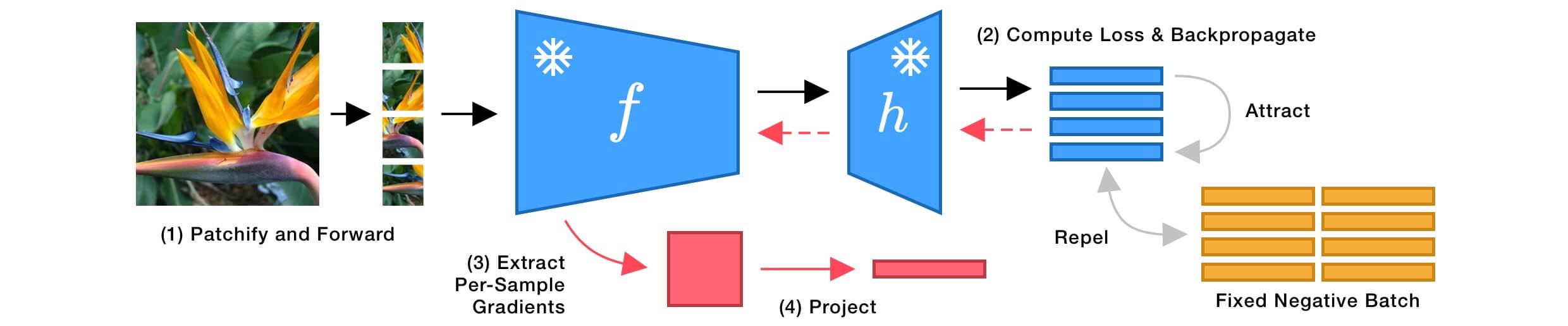
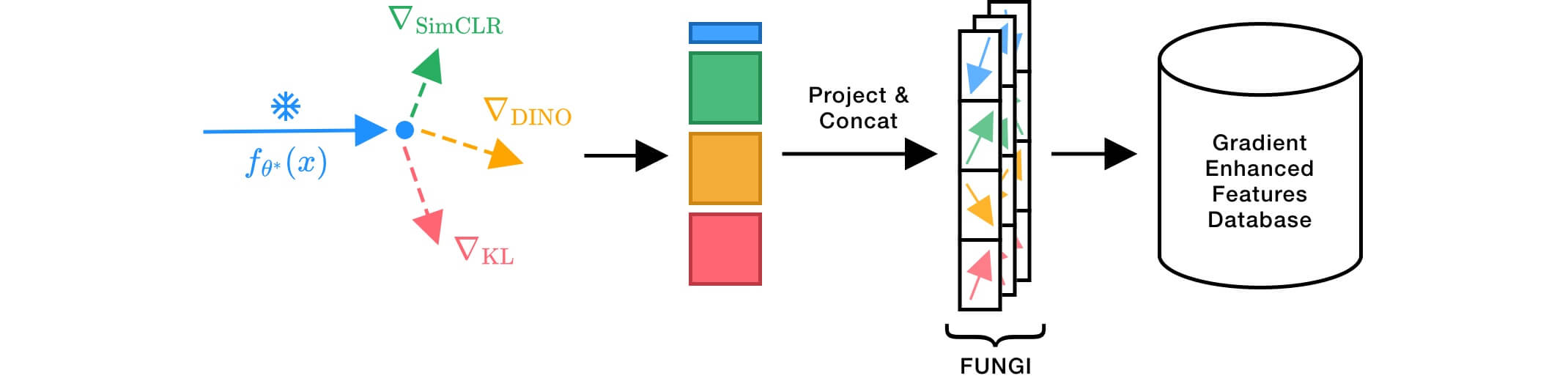
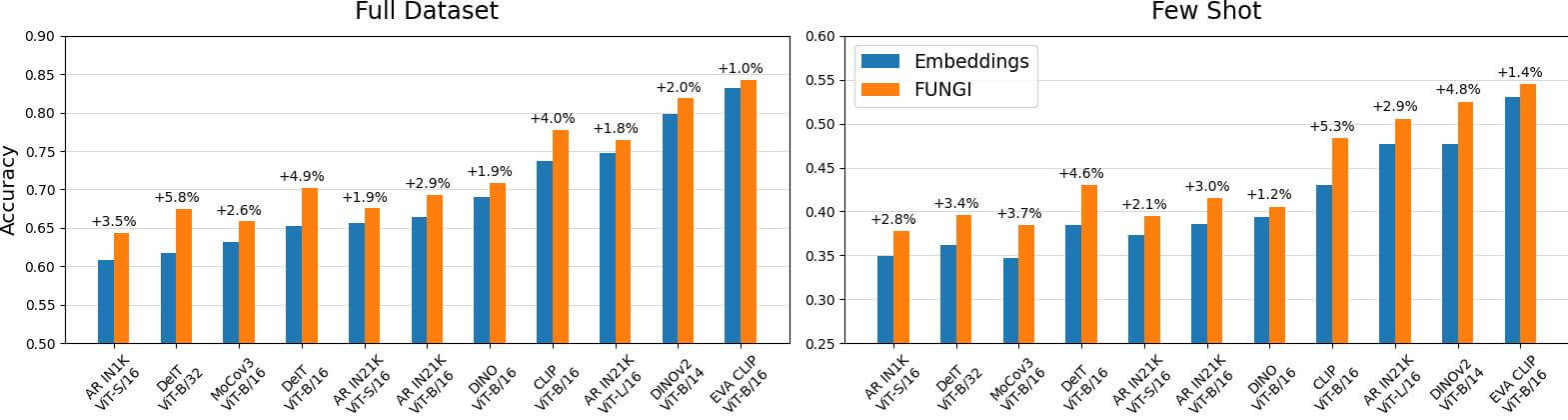
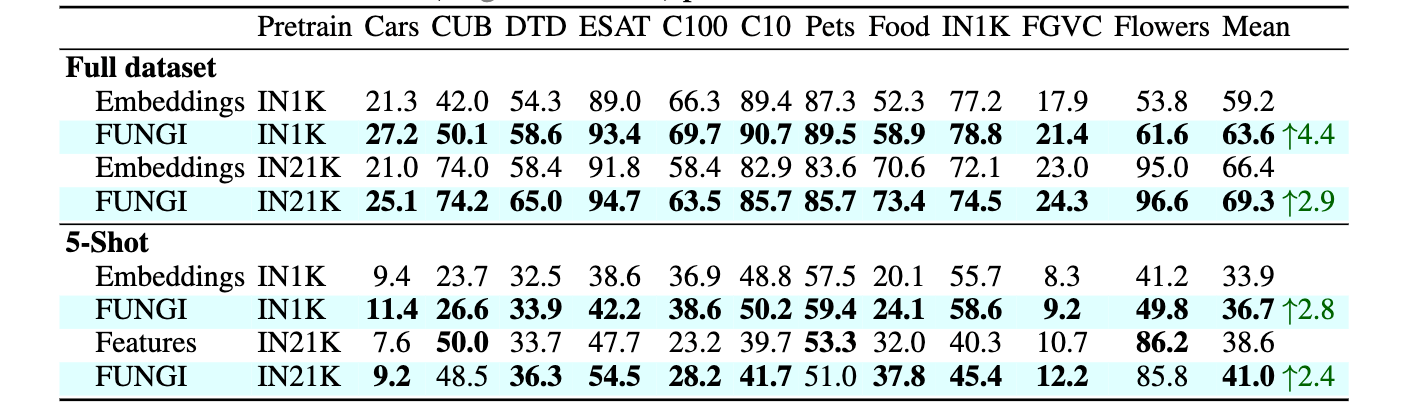

Pseudocode
We provide pytorch-like pseudocode for building FUNGI features by combining the model embeddings and the KL gradients. Please refer to our open-source code implementation for further details. If you just want to build FUNGI features without diving into the details check out our library fungivision.
# model: the vision backbone
# head: the projection head
# feat_dim: the model features dimensionality
# grad_dim: the gradients dimensionality (as a vector)
# projection: the random projection used to downsample gradients
projection = (torch.rand(feat_dim, grad_dim) - 0.5) > 0
uniform = torch.ones(feat_dim) / feat_dim
for x in dataset:
# Extract the feature and its projection
y = model(x)
z = head(y)
# Calculate the loss and backpropagate
loss = kl_div(log_softmax(z), softmax(uniform))
loss.backward()
# Select the target layer
layer = model.blocks.11.attn.proj
# Extract and project the gradients
gradients = torch.cat([
layer.weight.grad,
layer.bias.grad.unsqueeze(dim=-1)
], dim=-1)
gradients = projection @ gradients.view(-1)
# L2 normalize features and gradients independently
y, gradients = normalize(y), normalize(gradients)
# Build the final feature
feature = torch.cat([y, gradients], dim=-1)